I’m loudly claiming that 2013 will be a great year for web analytics solutions! Actually, that’s my two cents on this market I’m monitoring on an everyday basis from both a selling and a practical perspective.
So why 2013 should be a great year? Each of the top 4 web analytics solutions in North America (1) Google Analytics, (2) Adobe Analytics (ex-Adobe SiteCatalyst), (3) IBM Digital Analytics (ex-IBM Coremetrics) and (4) WebTrends, should all launch new features and it looks like it will be a battle of Titans. Furthermore, web analysts (not also to say financial analysts) will have to be delighted to adapt to these new features as the competition between these solutions will continue to be on the rise. In the following blog post, I will give you a personal overview of the state of the market.
Point 1 – State of the Market: Current Market Shares
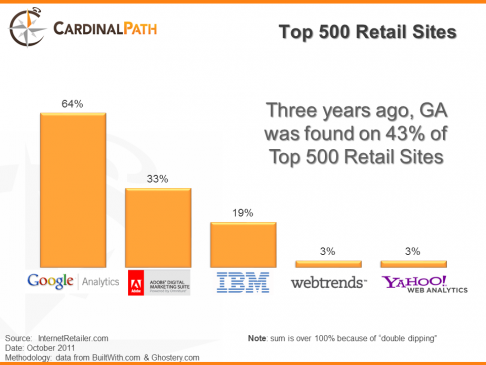
In terms of market shares for each web analytics solution, the most recent table I have under the belt dates back from mid-October 2011 by Stephane Hamel. Since that publication, Google Analytics Premium was launched less than a month after, Yahoo Analytics was closed down for Halloween 2012, and I would bet a Benjamin that the top two enterprise solutions (Adobe Omniture and IBM Digital Analytics) have both gained a larger portion of the pie – even though it’s an augmented pie since you can have more than one web analytics solution – when it comes to top 500 North American retailers. According to the graph below, it is quite clear that Google owns a huge chunk of the market, but are they the best positioned to dominate in 2013 in terms of revenues generated? More to come in the next section, surprise, surprise!
Point 2 – My two cents about each web analytics solution
1. Google with Google Analytics Premium
Google is the only top web analytics solution to have both a free and an enterprise version. While the company may be considered to own the market for web analytics, this is only the case in terms of usage, but not in terms of revenues since Google Analytics is free and Google Analytics Premium is used by only a small amount of companies worldwide. Even though Google owns the free web analytics solutions market, the company is considered as a laggard when it comes to the enterprise web analytics solutions market, the market that generates revenues. Does this mean that the company is topped in terms of market share potential? My rough guess is yes, but this also means that there is plenty of potential to transfer some free clients to an enterprise–level solution, but for this to happen, Google needs to find a way to convince customers of the free version to convert to an enterprise solution that could be considered as good as other enterprise web analytics solutions. For the coming year, I’m expecting a lot from all features related to Universal Analytics that were first announced during the Google Analytics Certified Partner (GACP) Summit held in October 2012 in Mountain View.
2. Adobe with Adobe Analytics
Adobe did a lot for their web analytics solution Adobe Analytics since they acquired Omniture in 2009. To solidify the branding, the web analytics solution even changed name from Adobe SiteCatalyst to Adobe Analytics. With their latest release, a new report called Time Prior to Event was introduced, here is a summary of Ben Gaines upcoming presentation at the Adobe Summit Digital Marketing from March 4th to March 8th 2013 in Salt Lake City.
3. IBM with IBM Digital Analytics
I am a firm believer that IBM has all it takes to eventually become the leader in the web analytics solutions market, necessarily because of how IBM Digital Analytics could be integrated with other IBM solutions. The complete integration between Unica and Coremetrics is still not over, but more and more the IBM Digital Analytics solution – which changed name from the initial IBM Coremetrics name in December 2012 – really looks like it’s making a name for itself. The initial plan in 2010 when IBM realized they bought both Coremetrics and Unica in the same year, was that IBM Coremetrics should be the IBM web analytics solution combining the best features of both Unica and Coremetrics while IBM Unica should be the IBM campaign management solution combining the best campaign management features from Unica and Coremetrics. Furthermore, according to a study by Forrester published in 2011 (note that this link shows only to a single table of the report), IBM Digital was at that time considered as the best web analytics solutions in terms of features. I’m looking forward for the Smarter Commerce Global Summit in Nashville from May 21st to May 23rd 2013.
4. WebTrends
Webtrends was the first true web analytics solution to be launched, dating back in 1995. Even though WebTrends is a great web analytics solutions, it will need sleepless nights for its resellers to keep up with the pressure of the other three giants. Maybe the Engage Webtrends event taking place in San Francisco in less than a week (January 28th to January 30th) will kickstart the year 2013.
Point 3 – Ownership as a Proxy for Potential Revenue Growth for Each Web Analytics Solution
So which company has the highest potential for 2013? Based on the ownership and market capitalization of each company, the answer seems straightforward here. IBM (219.74B) and Google 231.50B) are the two companies with the highest Market Capitalization, Adobe is way much lower at 18.77B but less diluted, and Webtrends looks like a David against Goliaths in terms of Market Capitalization. Even though, WebTrends Market Capitalization is not available since the company is private – my rough guess as of January 20th 2013 is that WebTrends is worth between half a billion and a billion based on how Omniture was sold in 2009.
Top 3 Predictions for 2013
As a conclusion to this post, here are my top 3 predictions for 2013 based on the last 3 points:
1. Google Universal Analytics will change the state-of-the-market finally embracing the Business Intelligence market and leaving the traditional Web Analytics grounds.
2. Adobe and IBM will continue to fight as top enterprise solutions players, trying to convert Google Analytics users to web analytics enterprise solutions users before Google Analytics Premium become more competitive.
3. WebTrends will have to be sold to a bigger player to stay in the race, either Google or Microsoft may be buyers.
Conclusion
As it is looking right now, in this Chinese year of the snake, the web analytics solution market will not be for snake charmers but more for bloody fight involving pythons and boas. Something is sure, whatever the web analytics solution used, what is most important is not the web analytics solution, it’s the web analyst using the solution :-),
Have a great year 2013 everyone,
Jean-Francois Belisle












{kind=link}